Excel Tabellendaten gruppieren
Daten aus einer Excel-Tabelle mit einer Formel gruppieren und sortieren.

Inhaltsverzeichnis
Excel bietet viele Möglichkeiten, um Tabellendaten zu analysieren und aufzubereiten. Gerade bei größeren Datenmengen ist es oft hilfreich, die Daten nach bestimmten Kriterien zu gruppieren und zu sortieren, um einen besseren Überblick zu erhalten.
In meiner täglichen Arbeit mit Excel stoße ich häufig auf Situationen, in denen ich Daten übersichtlich darstellen und auswerten muss. Dabei reichen die Standardfunktionen nicht immer aus. Insbesondere wenn die gruppierten Daten untereinander auf einem Arbeitsblatt angezeigt werden sollen, stößt man mit Bordmitteln wie Pivot-Tabellen oder dem Power Query Editor schnell an Grenzen.
Deshalb habe ich nach einer Lösung gesucht, um Tabellendaten flexibel mit Formeln zu gruppieren. Dabei sollen die Daten dynamisch nach den Werten in der ersten Spalte, zusammengefasst werden. Innerhalb der Gruppen soll man die Zeilen individuell sortieren können.
Vielleicht wird mein Vorhaben durch die Einführung der GROUPBY-Funktion einfacher werden. Diese Formel ist jedoch nur im Beta-Kanal von Excel verfügbar.
Nach einiger Recherche bin ich auf Reddit auf eine interessante Lösung gestoßen, die als Ausgangspunkt diente. Ich habe die Formel angepasst und möchte sie nun hier auf meinem Blog teilen.
Im Folgenden zeige ich wie die Formel aufgebaut ist und welche Excel-Funktionen dabei zum Einsatz kommen. Anhand eines praktischen Beispiels erkläre ich, wie man die Formel anwendet.
Voraussetzungen
- Microsoft 365 (Amazon Affiliate-Link)
Ausgangstabelle
Die Formel soll die Daten aus einer Tabelle (oder einem Bereich) nach der ersten Spalte gruppieren.
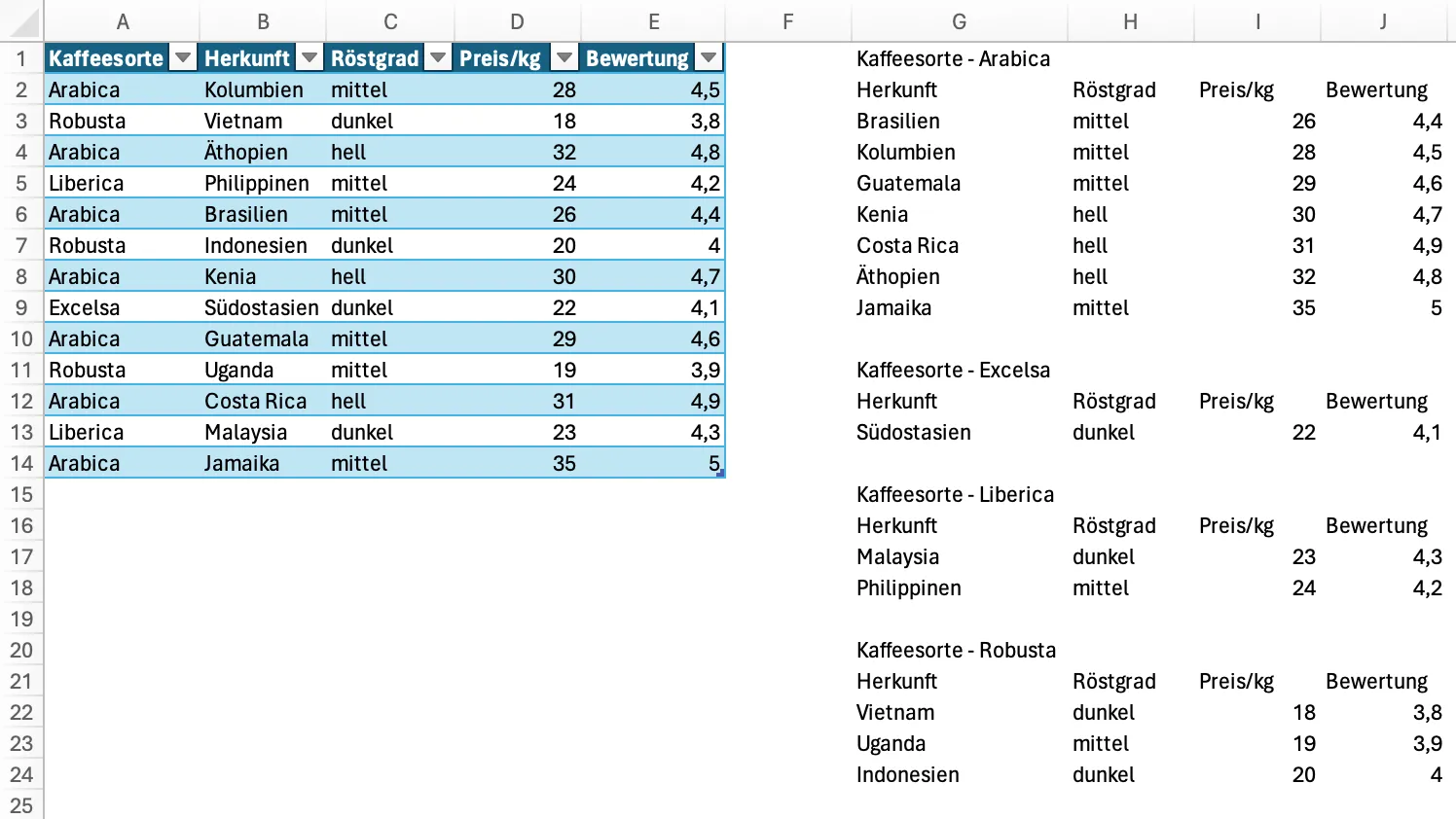
Nehmen wir an, wir haben folgende Tabelle:
| Kaffeesorte | Herkunft | Röstgrad | Preis/kg | Bewertung |
|---|---|---|---|---|
| Arabica | Kolumbien | mittel | 28,00 € | 4,5 |
| Robusta | Vietnam | dunkel | 18,00 € | 3,8 |
| Arabica | Äthiopien | hell | 32,00 € | 4,8 |
| Liberica | Philippinen | mittel | 24,00 € | 4,2 |
| Arabica | Brasilien | mittel | 26,00 € | 4,4 |
| Robusta | Indonesien | dunkel | 20,00 € | 4,0 |
| Arabica | Kenia | hell | 30,00 € | 4,7 |
| Excelsa | Südostasien | dunkel | 22,00 € | 4,1 |
| Arabica | Guatemala | mittel | 29,00 € | 4,6 |
| Robusta | Uganda | mittel | 19,00 € | 3,9 |
| Arabica | Costa Rica | hell | 31,00 € | 4,9 |
| Liberica | Malaysia | dunkel | 23,00 € | 4,3 |
| Arabica | Jamaika | mittel | 35,00 € | 5,0 |
Ziel
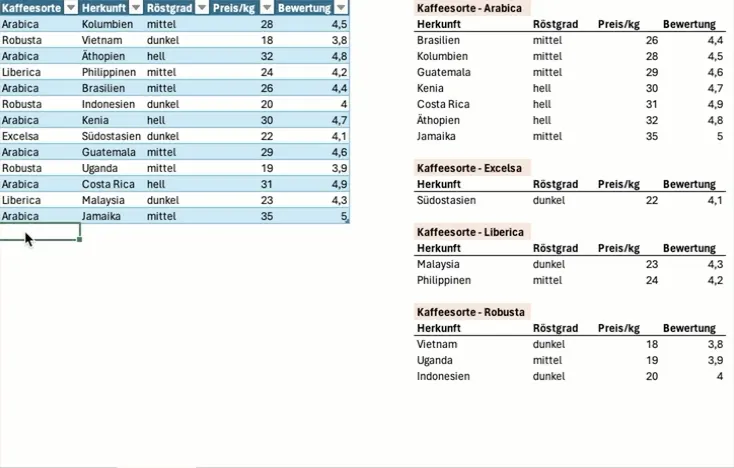
Die Formel soll die Daten nach der Kaffeesorte gruppieren. Innerhalb der Gruppen werden die Zeilen individuell sortiert. Das Ergebnis soll ungefähr so aussehen:
| Kaffeesorte | |||
|---|---|---|---|
| Arabica | |||
| Herkunft | Röstgrad | Preis/kg | Bewertung |
| Jamaika | mittel | 35,00 € | 5,0 |
| Costa Rica | hell | 31,00 € | 4,9 |
| Äthiopien | hell | 32,00 € | 4,8 |
| Kenia | hell | 30,00 € | 4,7 |
| Guatemala | mittel | 29,00 € | 4,6 |
| Kolumbien | mittel | 28,00 € | 4,5 |
| Brasilien | mittel | 26,00 € | 4,4 |
| Robusta | |||
| Herkunft | Röstgrad | Preis/kg | Bewertung |
| Indonesien | dunkel | 20,00 € | 4,0 |
| Uganda | mittel | 19,00 € | 3,9 |
| Vietnam | dunkel | 18,00 € | 3,8 |
| Liberica | |||
| Herkunft | Röstgrad | Preis/kg | Bewertung |
| Malaysia | dunkel | 23,00 € | 4,3 |
| Philippinen | mittel | 24,00 € | 4,2 |
| Excelsa | |||
| Herkunft | Röstgrad | Preis/kg | Bewertung |
| Südostasien | dunkel | 22,00 € | 4,1 |
Erklärung der verwendeten Excel-Funktionen
Um das zu erreichen werden mehrere Formeln benötigt.
EINDEUTIG
Gibt eine Liste der eindeutigen Werte in einem Bereich oder einem Array zurück.
=EINDEUTIG(A1:A10)Gibt eine Liste der eindeutigen Werte aus dem Bereich A1:A10 zurück.
| A |
|---|
| Apfel |
| Birne |
| Apfel |
| Banane |
| Birne |
Ergebnis:
| Eindeutige Werte |
|---|
| Apfel |
| Birne |
| Banane |
ERSTERWERT
Vergleicht einen Wert mit einer Liste von Werten und gibt das erste Ergebnis zurück, das der Bedingung entspricht.
=ERSTERWERT(A1; 1; "Ja"; 0; "Nein"; "Unbekannt")Vergleicht den Wert in A1 mit 1 und gibt “Ja” zurück, wenn er gleich ist, “Nein”, wenn er 0 ist, und “Unbekannt” für alle anderen Werte.
FILTER
Filtert ein Array basierend auf einer Bedingung und gibt das resultierende Array zurück.
=FILTER(A1:A5;A1:A5>3)Gibt alle Werte im Bereich A1:A5 zurück, die größer als 3 sind.
| A |
|---|
| 1 |
| 5 |
| 2 |
| 7 |
| 3 |
Ergebnis:
| Gefilterte Werte |
|---|
| 5 |
| 7 |
LAMBDA
Definiert eine benannte Funktion, die in anderen Formeln verwendet werden kann.
=LAMBDA(x; x * 2)(5)Definiert eine Funktion, die das Argument x mit 2 multipliziert und gibt das Ergebnis für x=5 zurück (10).
LET
Ermöglicht die Definition von benannten Variablen innerhalb einer Formel, um die Lesbarkeit und Wiederverwendbarkeit zu verbessern.
=LET(x; 5; y; 10; x+y)Ergebnis: 15. Die Variablen x und y werden innerhalb der LET-Funktion definiert und können in der Berechnung verwendet werden.
INDEX
Gibt einen Wert oder einen Verweis auf einen Wert an einer bestimmten Position in einem Bereich oder Array zurück.
=INDEX(A1:C5; 2; 3)Gibt den Wert in der zweiten Zeile und dritten Spalte des Bereichs A1:C5 zurück.
| A | B | C |
|---|---|---|
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
Ergebnis: 6.
MAP
Wendet eine Funktion auf jedes Element eines Arrays an und gibt das resultierende Array zurück.
=MAP(A1:A5; LAMBDA(x; x * 2))Multipliziert jedes Element im Bereich A1:A5 mit 2.
| A |
|---|
| 1 |
| 5 |
| 2 |
| 7 |
| 3 |
Ergebnis:
| Verdoppelte Werte |
|---|
| 2 |
| 10 |
| 4 |
| 14 |
| 6 |
MATRIXERSTELLEN
Erstellt ein Array basierend auf den angegebenen Dimensionen und einer Lambda-Funktion.
=MATRIXERSTELLEN(3; 3; LAMBDA(z; s; z * s))Erstellt ein 3x3-Array, bei dem jedes Element das Produkt aus Zeilen- und Spalten-Index ist.
MAX
Gibt den größten Wert in einer Liste von Argumenten zurück.
=MAX(A1:A5)Gibt den größten Wert im Bereich A1:A5 zurück.
REST
Gibt den Rest einer Division zurück.
=REST(10; 3)Gibt den Rest der Division von 10 durch 3 zurück (1).
SCAN
Führt eine Berechnung für jedes Element eines Arrays durch und gibt ein kumulatives Ergebnis zurück.
=SCAN(0; A1:A5; LAMBDA(kumulativ; wert; kumulativ + wert))Berechnet die kumulative Summe der Werte im Bereich A1:A5.
SEQUENZ
Erstellt ein Array von sequenziellen Zahlen basierend auf den angegebenen Parametern.
=SEQUENZ(5; 1; 1; 1)Erstellt ein Array mit den Zahlen 1 bis 5.
SORTIEREN
Sortiert die Zeilen einer Tabelle oder eines Bereichs basierend auf den Werten in einer oder mehreren Spalten.
=SORTIEREN(A1:C10; 2; -1)Sortiert den Bereich A1:C10 basierend auf den Werten in der zweiten Spalte in absteigender Reihenfolge.
SUMME
Addiert alle Zahlen in einem Bereich von Zellen.
=SUMME(A1:A10)Addiert alle Werte im Bereich A1:A10.
SPALTEN
Gibt die Anzahl der Spalten in einem Bereich oder einer Tabelle zurück.
=SPALTEN(A1:C5)Gibt die Anzahl der Spalten im Bereich A1:C5 zurück (3).
WEGLASSEN
Entfernt eine bestimmte Anzahl von Zeilen oder Spalten aus einer Tabelle oder einem Bereich.
=WEGLASSEN(A1:C5; 2; 1)Entfernt 2 Zeilen und 1 Spalte aus dem Bereich A1:C5, beginnend oben links.
WENN
Führt einen logischen Test durch und gibt einen Wert zurück, wenn das Ergebnis wahr ist, und einen anderen Wert, wenn es falsch ist.
=WENN(A1 > 10; "Größer als 10"; "Kleiner oder gleich 10")Überprüft, ob der Wert in A1 größer als 10 ist und gibt entsprechend “Größer als 10” oder “Kleiner oder gleich 10” zurück.
XVERGLEICH
Sucht nach einem bestimmten Element in einem Array oder Bereich und gibt die relative Position des ersten Treffers zurück.
=XVERGLEICH("B"; A1:A5; 0)Sucht nach dem Wert “B” im Bereich A1:A5 und gibt die relative Position zurück.
Formel
Die folgende Formel gruppiert die Daten nach der ersten Spalte und sortiert sie.
=LET(
sourceTable; Tabelle1[#Alle];
tableWithoutHeader; WEGLASSEN(sourceTable;1);
sortedTable; SORTIEREN(tableWithoutHeader;{1.3};{1.-1});
firstColumn; INDEX(sortedTable;;1);
uniqueValues; EINDEUTIG(firstColumn);
countOccurrences; 3+MAP(uniqueValues;LAMBDA(value; SUMME(--(value=firstColumn))));
runningTotal; SCAN(0;countOccurrences;LAMBDA(runningSum;count;runningSum+count));
differences; runningTotal-countOccurrences;
rowNumbers; SEQUENZ(MAX(runningTotal)-1);
lookupIndices; XVERGLEICH(rowNumbers;runningTotal;1);
remainders; REST(rowNumbers-INDEX(differences;lookupIndices);INDEX(countOccurrences;lookupIndices));
outputTable; MATRIXERSTELLEN(
MAX(runningTotal)-1;
SPALTEN(sourceTable)-1;
LAMBDA(rowNum;colNum;
ERSTERWERT(
INDEX(remainders;rowNum);
0;"";
1; WENN(colNum=1;" "&INDEX(uniqueValues;INDEX(lookupIndices;rowNum));"");
2; INDEX(sourceTable;1;colNum+1);
INDEX(
FILTER(sortedTable;firstColumn=INDEX(uniqueValues;INDEX(lookupIndices;rowNum)));
INDEX(remainders;rowNum)-2;
colNum+1
)
)
)
);
outputTable
)Anwendung
- Kopiere die Formel in eine Zelle.
- Passe den Bereich bei
sourceTablean. - Passe die Sortierung bei
sortedTablean. - Passe bei
outputTabledie Überschriften an (z. B.[...]1;WENN(colNum=1;"Kaffeesorte - "&[...])).
Das Ergebnis sollte dann so aussehen:
Mit bedingter Formatierung können auch die Überschriften hervorgehoben werden.
Alternativen
Müssen die Daten nicht in diesem Format angezeigt werden, kann auch die Pivot-Tabelle verwendet werden. Diese ist einfacher zu erstellen und zu pflegen. Wenn die Daten nebeneinander angezeigt werden sollen, reicht schon die FILTER-Funktion zum größten Teil aus.
Fazit
Mit dieser Formel können Tabellendaten in Excel basierend auf einer Spalte gruppiert und sortiert werden. Die Formel verwendet verschiedene Excel-Funktionen wie LET, WEGLASSEN, SORTIEREN, EINDEUTIG, MAP, SCAN, SEQUENZ, XVERGLEICH, REST, MATRIXERSTELLEN und ERSTERWERT, um die gewünschte Ausgabe zu erzeugen.